Tive necessidade de baixar um documento do Issuu. Segue um script simples que escrevi para baixar as páginas, convertê-las para PDF e mesclá-las. Ele não tem checagem de erros, mas pode ser útil para mais pessoas:
O script requer Bash, wget, GhostScript e ImageMagick. A maioria das distribuições de Linux já tem esses aplicativos, mas por via das dúvidas cheque se você tem o ImageMagick instalado.
RTMP (Real Time Messaging Protocol) é um protocolo desenvolvido pela Macromedia para fazer streaming de áudio e vídeo de um servidor para um Flash player.
Vou mostrar uma forma genérica para baixar vídeos de sites que usam RTMP usando como exemplo um vídeo do Deutsche Welle. Escolhi esse site porque ele não é suportado pela extensão Video DownloadHelper do Firefox. Porém, a dica funciona para vários outros sites que também usam esse protocolo.
Para começar, você vai precisar instalar dois programas livres: Wireshark e RTMPDump.
O primeiro serve para analisar os pacotes que estão passando na rede (quem manda para quem, que protocolo está sendo usado, qual seu conteúdo etc). O segundo baixa vídeos que estão disponíveis através do protocolo RTMP.
Para instalá-los no Ubuntu, basta escrever num terminal: sudo apt-get install wireshark rtmpdump. Em outras distribuições de Linux, use seu gerenciador de pacotes preferido.
No Windows ou outras plataformas onde é mais difícil instalar programas, você pode baixar esses programas (e seus códigos) em wireshark.org e rtmpdump.mplayerhq.hu.
Antes que reclamem nos comentários, há muitos programas mais simples que poderiam substituir o Wireshark nessa dica, mas decidi usar o Wireshark porque ele permite muitas outras coisas que podem ser úteis no futuro. Com efeito, usando o Wireshark é fácil encontrar o endereço de vídeos de sites que usam Flash mas não usam RTMP, como por exemplo Globo.com (que usa HTTP mesmo). Além disso, o Wireshark pode ajudar você a capturar e analisar pacotes que estão passando pelo ar mas teoricamente não deveriam ser lidos por você numa rede WiFi. Porém, isso já foge do escopo deste post.
O vídeo que usarei como exemplo é o que aparece quando você clica na foto do Brasil (Organize a sua indignação) na reportagem Alle Macht dem Volk? Clique nessa imagem e deve aparecer uma tela como esta:
Tela que aparece ao clicar num vídeo numa reportagem do Deutsche Welle.
Neste momento, espere um pouco antes de clicar no botão Play para começar a tocar o vídeo. Primeiro abra o Wireshark e comece a capturar na interface que você usa para acessar a Internet (ou escute em todas caso não saiba qual escolher). Para não ter que ficar vendo muitas coisas desnecessárias, filtre apenas mensagens do protocolo RTMP: escreva no campo Filter o valor rtmpt (não é erro de digitação, tem um “t” no final mesmo) e pressione Enter.
Agora você pode começar a tocar o vídeo. Porém, não é de seu interesse assistí-lo no navegador e você não quer que o Wireshark fique muito sobrecarregado capturando todos os milhares de pacotes que passam na rede para transferir um vídeo desse tamanho. Portanto, inicie o vídeo e, assim que ele começar a tocar, feche a aba para parar de baixá-lo.
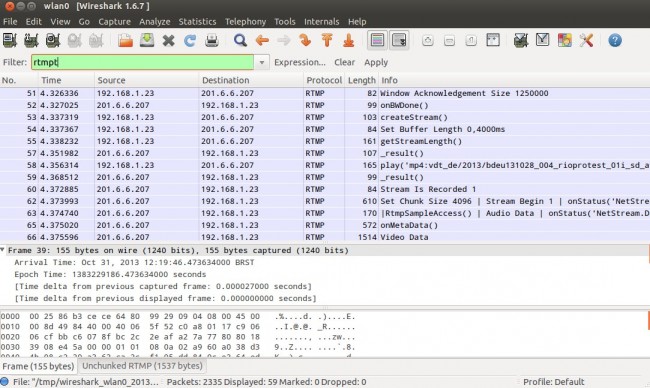
Se tudo correu bem, você pode parar a captura no Wireshark (clicando no ícone vermelho com um X lá no seu menu). Na sua tela, você deve estar vendo alguns pacotes RTMP filtrados:
Pacotes filtrados no Wireshark
Lendo o conteúdo desses pacotes, você consegue descobrir qual é o endereço do vídeo no protocolo RTMP e então usar o RTMPDump para baixá-lo. Esse endereço está dividido em duas mensagens.
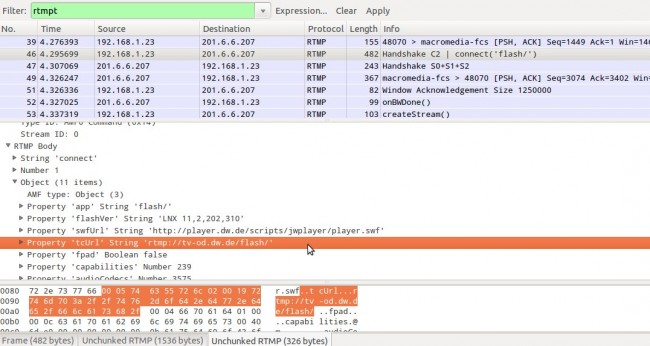
Na mensagem connect enviada pelo cliente ao servidor para iniciar o handshake, você encontra o parâmetro tcUrl, que neste caso aponta para rtmp://tv-od.dw.de/flash/:
Parâmetro tcUrl no Wireshark.
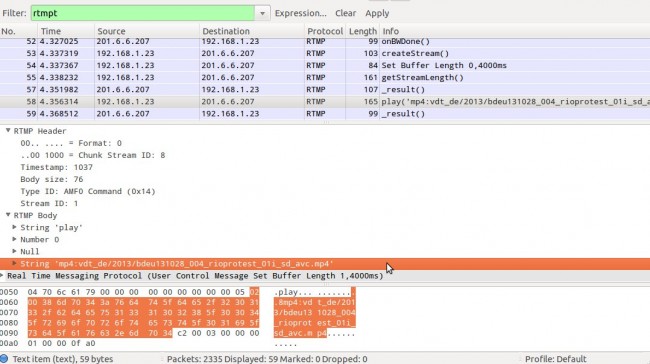
Um pouco abaixo, na mensagem play, você encontra o resto do endereço (neste caso, vdt_de/2013/bdeu131028_004_rioprotest_01i_sd_avc.mp4):
O resto do endereço do vídeo no corpo do RTMP.
Juntando as duas partes, temos o endereço completo: rtmp://tv-od.dw.de/flash/vdt_de/2013/bdeu131028_004_rioprotest_01i_sd_avc.mp4. Com ele, é hora de usarmos o RTMPDump. Essa parte é trivial. Basta abrir um terminal e digitar rtmpdump com os parâmetros -r (endereço) e -o (arquivo de saída). O resultado é este:
Me acostumei a usar o legendas.tv para baixar legendas de filmes e acabei nunca me perguntando se haveria um jeito mais fácil de baixá-las. Hoje fui assistir um filme e, ao entrar no navegador para baixar sua legenda, me deparei com a mensagem de que o site estava fora do ar:
Mensagem do legendas.tv fora do ar.
A situação me obrigou a procurar outros sites e outras formas de baixar legendas. Minha primeira ideia foi usar o opensubtitles.org, que já havia usado algumas outras vezes. Chegando lá e procurando pelo filme que eu desejava, vi muitas opções e não estava muito claro que legenda baixar para a versão do filme que eu tinha.
Então resolvi dar uma fuçada na pesquisa avançada do site, onde acabei encontrando uma pesquisa por hash. Hash, em computação, é uma função que “resume” uma informação gigante (tipo um arquivo bem grande) numa informação bem pequena (tipo 16 caracteres) que o represente de forma única (ou quase única). A pesquisa por hash, no caso desse site, consiste em procurar uma legenda utilizando esse “ID” do arquivo (ou seja, não importa seu nome).
Achei a possibilidade tão legal que resolvi fazer um programa para nunca mais precisar abrir o navegador quando eu quiser baixar a legenda de um filme. Escrevi um minúsculo programa em C chamado oshash (de OpenSubtitles Hash) para calcular o hash de um filme de acordo com a especificação do site (que não requer nada, a não ser um compilador de C e a biblioteca padrão) e um script (bem tosco, mas funcional) chamado downloadsubtitle que usa o programa oshash (e pequenos programas que todo mundo tem, tipo grep, sed, wget e unzip) para baixar a legenda.
O funcionamento ficou bem fácil: para baixar uma legenda em qualquer língua, basta você digitar downloadsubtitle arquivo.avi para baixar a legenda do “arquivo.avi” (que já vai ser automaticamente nomeada como “arquivo.srt”). Se você quiser especificar uma língua (por exemplo, português do Brasil), é só digitar downloadsubtitle arquivo.avi pob (pob é o código do português do Brasil). Se você quiser baixar uma legenda em inglês ou espanhol, pode usar downloadsubtitle arquivo.avi eng,esp.
Exemplo de funcionamento
$ ls
Amelie [Amélie Poulain].2001.BRRip.x264.AAC[5.1]-VLiS.mkv
$ downloadsubtitle Amelie\ \[Amélie\ Poulain\].2001.BRRip.x264.AAC\[5.1\]-VLiS.mkv pob
Requested language: pob
Movie hash: bcdc90cf4873c09b
Subtitle ID: 4642726
Subtitle: Amelie [Amélie Poulain].2001.BRRip.x264.AAC[5.1]-VLiS.srt
$ ls
Amelie [Amélie Poulain].2001.BRRip.x264.AAC[5.1]-VLiS.mkv Amelie [Amélie Poulain].2001.BRRip.x264.AAC[5.1]-VLiS.srt
$
E aí o filme está pronto para você assistir com o mplayer ou com o seu programa favorito.
Código
Este é o código inicial. Está aqui para fins históricos. Não será atualizado. Use a próxima seção (Download) para baixar a última versão, com bugs corrigidos, tratamento de erros e possivelmente novas funcionalidades.
#include<stdio.h>#include<stdlib.h>voidusage(char*name){printf("Usage: %s <file>\n", name);exit(1);}intmain(int argc,char*argv[]){unsignedlonglong buf[16384], c =0;
FILE *in;int i;if(argc !=2){usage(argv[0]);}
in =fopen(argv[1],"rb");if(in ==NULL){usage(argv[0]);}fread(buf,8192,8, in);fseek(in,-65536,SEEK_END);fread(&buf[8192],8192,8, in);for(i =0; i <16384; i++){
c+= buf[i];}
c+=ftell(in);fclose(in);printf("%016llx\n", c);return0;}
O programa ainda não está empacotado bonitinho (não tem nem Makefile ou instruções de instalação). Se futuramente vier a ter, este post será atualizado. Em resumo, basta compilar o código em C (digitando gcc oshash.c -o oshash) e colocar os arquivos oshash e downloadsubtitle numa pasta do seu $PATH (por exemplo, /usr/local/bin).
Como o Ibrahim e a mídia tradicional já noticiaram, o sétimo livro da série da autora J. K. Rowling, Harry Potter e as relíquias da morte (Harry Potter and the Deathly Hallows), já está inteiro disponível para download através de torrentsinternet a fora.
A editora Scholastic e a autora Joanne Kathleen Rowling não comentam sobre a autenticidade das cópias virtuais, o que é indício de que elas são mesmo reais. Eu passei os olhos pelo PDF e li algumas páginas (principalmente do final, como todo bom curioso) e acredito que este livro divulgado na internet é mesmo o verdadeiro livro 7 de Harry Potter.
Pelo o que eu entendi, Harry Potter não morre, o último capítulo é dezenove anos depois do resto da história, nas últimas páginas há um diálogo sobre a Sonserina (Slytherin), o diálogo entre Harry e Voldemort no penúltimo capítulo é super interessante (e não vou contar que é sobre a “morte” de Dumbledore e a “lealdade” de Snape) e há muitas mortes e “ressurreições”.
Diferentemente de fãs que vestem a roupa dos personagens e soltam feitiços pelas ruas, eu gosto bastante da série de Rowling, mas sou um leitor passivo. Eu adoro ler best-sellers (ex: Dan Brown), por mais que pessoas muito cultas digam que isso é perda de tempo e que não é literatura. Felizmente, eu não ligo pro que é literatura e não ligo por “perder” meu tempo para me divertir um pouquinho, então eu leio mesmo Harry Potter. Tenho todos os livros aqui em casa e vou esperar versões escaneadas (não fotografadas) do sétimo volume saírem na internet para baixar e ler com mais conforto.