Esses dias, tomando banho de mar, me vi pensando na forma das potências de dois em base dez.
É fácil ver que não existe potência de 2 que termine em 0, já que qualquer número que termina em 0 é múltiplo de 5.
Na verdade, é fácil ver (com um raciocínio indutivo com módulo 10) que o último algarismo das potências de 2 vai seguindo a sequência (2, 4, 8, 6) infinitamente, de tal forma que o último algarismo de 2k (k > 0) é:
6, se o resto da divisão de k por 4 for 0
2, se o resto da divisão de k por 4 for 1
4, se o resto da divisão de k por 4 for 2
8, se o resto da divisão de k por 4 for 3
Mas aí fiquei pensando em potências de 2 que acabassem com uma porção de doises. Algo como 3103912840123891294805398108310312222 (esse número aí não tem nada de especial, foi só eu batendo no teclado loucamente e terminando com 2222). Como eu faria pra encontrá-las? Será que existem?
Comecei pensando em coisas do tipo 222…222, isto é 2×10n+2×10n−1+2×10n−2+⋯+2×100.
Podemos colocar 20 em evidência, ficando com 20×(10n−1+10n−2+⋯+100)+2.
A princípio isso não parece ajudar muito, mas vejam que interessante:
20×x+2=2(10x+1) (x é qualquer número inteiro > 0)
Bem… 10x+1 certamente não é uma potência de 2 (porque termina em 1).
Logo, 2(10x+1) também não é uma potência de 2, independente da maluquice que a gente coloque no lugar de x.
Portanto, não existem potências de 2 que terminem em 22! Mais que isso: não existem potências da forma 20x+2, ou seja, não existem potências de 2 que terminem em 02, 22, 42, 62 ou 82! Não é incrível? Não é nada muito revolucionário ou complexo, mas nunca tinha parado pra pensar nisso.
Lá no início tínhamos visto que o último algarismo de 2k é 2 se e somente se o resto da divisão de k por 4 for 1. Logo, concluímos (e dá pra imaginar várias outras provas simples pra esse fato, pensando bem, por exemplo notando que 12×16≡12mod20) que para todo k > 0 tal que o resto da divisão de k por 4 seja 1 vale que o resto da divisão de 2^k por 20 é 12.
As primeiras potências de 2 que terminam em 2 são:
21=2 (que ignorei aí em cima quando falei que x > 0 no 20x+2)
25=32
29=512
213=8192
217=131072
221=2097152
225=33554432
O que parece nos indicar que, da mesma forma que o último algarismo das potências de 2 seguem a sequência (2, 4, 8, 6), o penúltimo algarismo das potências de 2 que acabam em 2 seguem a sequência (9, 7, 5, 3, 1). Isso é fácil de ver: basta fazer umas multiplicações por 16 dentro do módulo 100.
Fui surpreendido hoje à noite pela notícia de que internautas tiraram do ar o site nacional do PSOL por 10 horas. O motivo: #OpImagemLimpa, de algumas pessoas que bizarramente acham que detêm o título de “os únicos anônimos dignos de usarem a máscara do Guy Fawkes”:
Aprendão a não usar a imagem do #Anonymous, não censurem seus usuários – #OpImagemLimpa – Ataques, Defaces e Divulgação de dados de todas as pessoas e grupos que estão usando nossa imagem de má fé! –
Quero fazer algumas poucas considerações breves e, fraternalmente, dar algumas sugestões aos companheiros que participaram dessa operação, na minha opinião, bastante infame.
Anônimos com A maiúsculo surgiram num momento em que o mundo se mobiliza por democracia real: nas praças do mundo árabe onde derrubaram ditaduras, nas ruas da Europa em busca de alternativas para que os trabalhadores não paguem pela crise econômica, na defesa da democratização dos meios de comunicação e da internet ao lado do Wikileaks e de Julian Assange, defendendo que ninguém tire sites arbitrariamente na internet e com uma multidão tirando do ar sites de Visa, Mastercard e Paypal para repudiar essas empresas que apoiaram a tentativa do governo americano de acabar com o Wikileaks.
Anônimos não são um coletivo organizado. Anônimos somos todos nós, que queremos usar a internet sem expôr a nossa identidade, todos nós em movimento e com toda nossa diversidade, todos que juntos nos mobilizamos e vamos pras ruas independente de raça, origem ou religião, e que usamos uma máscara que representa a liberdade — uma máscara que jamais deve ser pretexto para a censura e para o desrespeito. Ninguém é dono do título de anônimo, decide quem é anônimo e quem não é, quem usa a máscara e quem não usa.
O site nacional do PSOL é um site que divulga as lutas populares, dos trabalhadores em greve, das mulheres, do movimento LGBT, as mobilizações em curso do Chile a Grécia, denuncia a tentativa de golpe no Paraguai se contrapondo à mídia tradicional e apresentando alternativas que querem romper com a politicagem naturalizada, como Freixo no Rio. Seja você do PSOL ou não, anônimo ou não, por que derrubar esse site? É esse seu maior inimigo? A que serve derrubar o site do PSOL? Quem sai ganhando quando nos dividimos são os capitalistas, o 1%, que ao fragmentarem os 99% fazem com que nós percamos a noção de que fazemos parte de uma só classe neste sistema e que devemos lutar juntos para superá-lo.
É fácil derrubar um site como o do PSOL. É o site de um partido independente a grandes banqueiros e empresários, que não gasta dinheiro num super datacenter. Realizar um DDoS lá não tem nada de desafiador, de hacker ou de incrível; é só pura falta do que fazer mesmo.
Que tal usarmos a nossa energia para algo útil? Em vez de só ficarmos defendendo uma máscara como se ela tivesse dono (no melhor estilo da indústria do copyright) e congestionando sites arbitrariamente, que tal defendermos a internet livre e democrática, onde todos podemos participar e expôr nossas ideias, como defendeu todo o movimento em torno do Wikileaks que deu origem a Anônimos como substantivo próprio? Contra a retirada do sites do ar, e não a favor.
Que tal criar sites de mídia alternativa (como o Juntos, o Jornalismo B, o blog do Tsavkko e tantos outros), usar a internet para fazer as notícias que o governo e a mídia não querem que cheguem nas pessoas chegarem? Ou ainda que tal defacear os sites da mídia tradicional pra expôr a greve dos professores federais que não é noticiada, as contradições dos governos e da velha política que une PT a Maluf em São Paulo?
São desafios bem maiores que tirar um site como o do PSOL nacional do ar, que precisam de muitos anônimos e não-anônimos unidos para serem colocados em prática e que contribuem muito mais para criarmos um novo sistema econômico e social, com democracia real, igualdade e liberdade para todos. Além de fazerem muito mais justiça ao legado da máscara de Guy Fawkes.
Editado em 24/06 às 13:13 pra adicionar o texto abaixo:
Mas resta uma dúvida: afinal, qual foi o “crime” que motivou esse protesto? Teria o site do PSOL nacional cometido a terrível transgressão de veicular alguma foto com uma máscara preto e branca como essa? Teria alguém comentado em algum lugar da internet com o nome Anônimo reivindicando ou pedindo votos para o PSOL (barbaridade que, cá entre nós, merece a sentença de cortar uma mão fora além de tirar o site do PSOL do ar pra todo o sempre)? É pior que isso, acreditem. Um companheiro de Brasília me escreveu um e-mail pra contar:
O Twitter @PSOLMESDF recomendou um perfil desses anônimos iluminados que acham que são os únicos anônimos da internet num #FollowFriday. A resposta desse Anônimo foi: @PSOLMESDF ta loco??? pq ta me indicando, sou apartidario! vão se foder! e logo em seguida: Galera preciso de uma ajuda, denunciem este perfil @PSOLMESDF , o fdp ta tentando sujar a ideia #anonymous. Não é fantástico? Retuitar ou dar follow friday para um desses caras é denegrir a sua imagem e merece protestos. É suficiente para o site de um partido sair do ar por 10 horas.
Bom… Prefiro pensar que as pessoas que participaram dessa operação não sabiam o motivo. O mínimo que alguém decente esperaria seria um pedido de desculpas, mas, caros anônimos (na verdade, uma pequeníssima parte dos anônimos que teve a ver com isso), tudo bem se o orgulho de vocês não permitir isso: Só peço que vocês pensem melhor no que estão fazendo da próxima vez e estejam do lado de quem quer construir uma internet com liberdade e democracia, não uma de censura e arbitrariedades.
(e um abraço a todos que me mandaram mensagens me xingando por eu ter cometido o terrível erro de escrever a verdade: o que vocês fizeram foi um absurdo)
Escrito em PHP. Pode ser usado no tema do seu WordPress. Requer CURL. Faz cache do calendário para não ter que baixá-lo sempre que alguém entra no seu site. Desenvolvido para um site que vai sair nos próximos dias. Use, modifique e distribua como quiser. (Não me responsabilizo por qualquer problema. Fiz pra um caso específico. A checagem de erros é meio porca.)
<?phpdate_default_timezone_set('America/Sao_Paulo');$events=Array();$dom=newDOMDocument();$file="cached_calendar.xml";$last=-1;if(file_exists($file)){$last=filemtime($file);}// Mude 3600 para o tempo (em segundos) que você quiser que o cache expireif(time()-$last>3600){$fp=fopen($file,"w+");if(!$fp){die();}// Substitua o e-mail do calendário do Google CodeJam pelo e-mail do seu calendário (público)$ch=curl_init("https://www.google.com/calendar/feeds/"."google.com_jqv7qt9iifsaj94cuknckrabd8%40group.calendar.google.com/public/full");curl_setopt($ch,CURLOPT_TIMEOUT,50);curl_setopt($ch,CURLOPT_FILE,$fp);curl_exec($ch);curl_close($ch);fclose($fp);}$dom->load($file);$feed=$dom->getElementsByTagName("feed");$entries=$feed->item(0)->getElementsByTagName("entry");foreach($entriesas$entry){$children=$entry->getElementsByTagName("*");$day="";$start="";$end="";foreach($childrenas$child){switch($child->tagName){case"title":$title=$child->nodeValue;break;case"gd:when":if($child->hasAttribute("startTime")){$st=strtotime($child->getAttribute("startTime"));$time_to_sort=$st;$day=date_i18n("l, d/M",$st);$start=date("H:i",$st);}if($child->hasAttribute("endTime")){$et=strtotime($child->getAttribute("endTime"));$end=date("H:i",$et);}break;}}if($title!=""&&$day!=""){$events[]=Array("time_to_sort"=>$time_to_sort,"day"=>$day,"start"=>$start,"end"=>$end,"title"=>$title);}}functioncmp($a,$b){$a=$a["time_to_sort"];$b=$b["time_to_sort"];if($a==$b){returnstrcmp($a["title"],$b["title"]);}return($a<$b)?-1:1;}usort($events,"cmp");$n=count($events);if($n>0){$lastDay="";for($i=0;$i<$n;$i++){$day=$events[$i]['day'];$title=$events[$i]['title'];$start=$events[$i]['start'];$end=$events[$i]['end'];if($lastDay!=$day){if($i!=0){echo"</ul>\n\n";}echo"<h3 class="day"><span>$day</span></h3>\n";echo"<ul>\n";}echo"\t<li>\n";if($start!=""){// Você pode modificar aqui para mostrar o horário de término ($end).echo"tt<span class="time">{$start}</span>\n";}echo"\t\t<strong>{$title}</strong>\n";echo"\t</li>\n";$lastDay=$day;}echo"</ul>\n";}else{echo"<p>Nenhum evento cadastrado.</p>\n";}?>
Suppose you have a lot of .doc, .docx, .xls, .xlsx, .gz, .bz2, .pdf and text in general (.csv, .txt etc.) files and want to dump all the (unique) email addresses from them. How would you do it? Here is a simple solution I’ve just implemented (and probably didn’t test enough, so tell me if you find any bug):
Se você não é nerd, não tem tempo, não tem coração e não tem curiosidade, recomendo que ignore todo o texto e leia somente o item 3.
Por causa da forma como os álbuns de fotos do UOL são feitas, copiar suas fotos é uma tarefa difícil para a maioria dos usuários. Não acho que a UOL faça assim de propósito, mas por uma questão de usabilidade mesmo: há dois botões enormes em cima das fotos para você avançar para a próxima foto ou voltar para a anterior, e é por causa deles que você não consegue ver o “Copiar endereço da imagem” quando clica com a tecla direita na área da imagem (porque você não está realmente clicando na imagem, mas num botão transparente).
No entanto, há várias formas de copiar fotos dos álbuns da UOL. Neste post apresento algumas. Para testar, você pode tentar aplicar essas ideias neste álbum.
0. Soluções toscas
Como eu disse no início, os webmasters do UOL aparentemente não fazem os álbuns se comportarem assim de propósito, mas por causa de botões gigantes. A maneira mais fácil de copiar uma foto de um álbum do UOL é clicar bem na coluna exatamente no meio dela, evitando as duas setas. Você pode passar o mouse devagar pelo meio da foto até que o seu cursor deixe de ser uma mãozinha e seja uma seta. Pra saber se você deve ir pra esquerda ou pra direita é só ir na direção da seta que você não está vendo.
Clicando com a tecla direita no meio da foto
Outra solução também tosca é simplesmente tirar um screenshot da tela em que você está (apertar a tecla PrintScreen na maioria dos computadores deve funcionar) e recortar a imagem. Eu imagino que essa seja a solução mais usada, mas pessoalmente acho ela terrível.
Não pare de ler! Prometo que as próximas soluções vão ser mais legais.
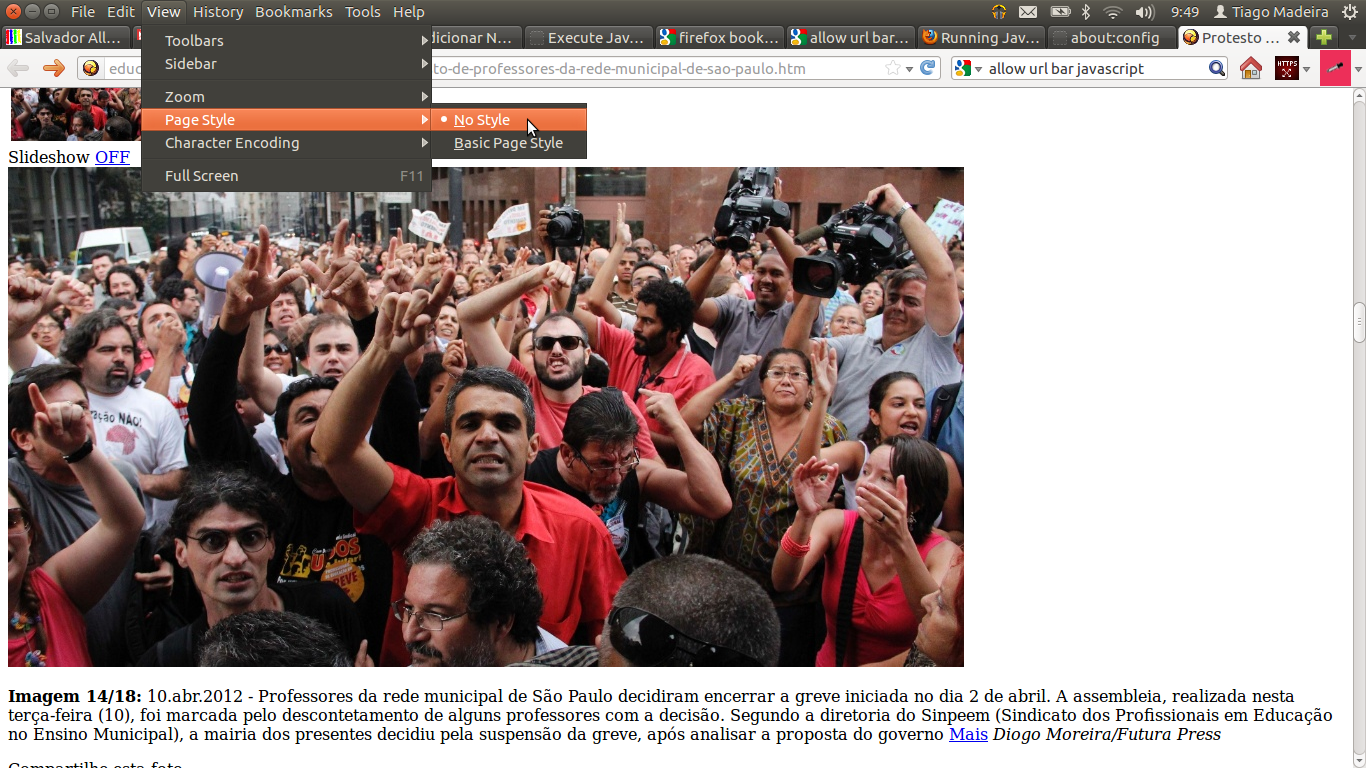
1. Somente para o Firefox: desativar estilos
Desativar o CSS da página é uma forma fácil de acabar com todo seu leiaute e dessa forma copiar a imagem sem se preocupar com perfumarias. Você provavelmente pode fazer isso em qualquer navegador usando plugins (e nos navegadores que não suportam CSS é até mais fácil: você nem precisa fazer nada!) e no Firefox em particular há um botão no menu (Exibir » Estilos » Sem estilos).
Página do álbum de fotos com estilos desativados no Firefox
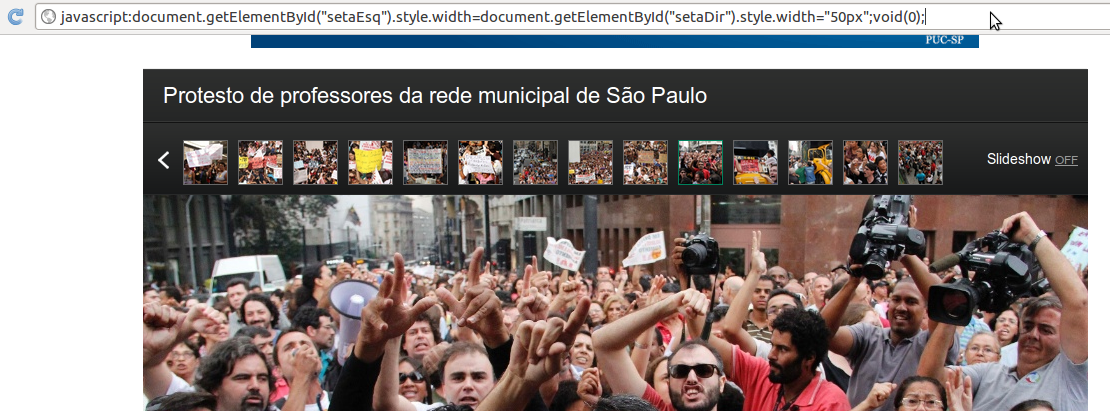
2. JavaScript na barra de endereço
Em geral, você pode escrever um script na barra de endereço para executá-lo na página em que você está. Há um tempo atrás todos os navegadores aceitavam isso, mas aparentemente muitos têm desativado esse recurso por questões de segurança, inclusive o Firefox. De qualquer maneira, se seu navegador suportar, você pode simplesmente digitar:
na barra de endereço quando estiver na página do álbum do qual quer baixar fotos.
Digitando JavaScript no campo da URL do navegador
Isso vai reduzir o tamanho dos botões, fazendo com que a área clicável seja bem maior.
Exercício para quem souber ou quiser aprender JavaScript: Escreva um script que abra a foto numa nova aba em vez de simplesmente deixá-la clicável. Transforme-o num bookmarlet (veja o próximo item).
3. Bookmarlet
A solução anterior nos incentiva a criar um botão que execute esse script para não termos que decorá-lo nem copiá-lo sempre. Eis aqui esse botão para você: Aumentar área clicável das fotos dos álbuns da UOL. Clique com a tecla direita nesse link e adicione-o aos seus favoritos. Quando você estiver num álbum, clique nesse favorito e a imagem vai se tornar magicamente clicável :)
4. Firefox e GreaseMonkey
Se você usa Firefox e tem instalada a extensão GreaseMonkey, instale o seguinte user script (que executa o mesmo código que colei no item 2) e sempre que você abrir um álbum as fotos serão clicáveis: Download do userscript
// ==UserScript==// @name Copiador de fotos UOL// @description Torna mais fácil copiar fotos de álbuns da UOL// @author Tiago Madeira <contato@tiagomadeira.com>// @include http*://*.uol.com.br/album/*// @version 0.9// ==/UserScript==(function(){
window.onload=function(){
document.getElementById("setaEsq").style.width ="50px";
document.getElementById("setaDir").style.width ="50px";};})();
Mas estou lendo este post em 2020 e o UOL mudou! Ou eu quero baixar fotos do site X, não do UOL!
A solução 1 (desativar estilos) funciona em 99% dos casos. Não quer ver sites sem estilo? Continue lendo.
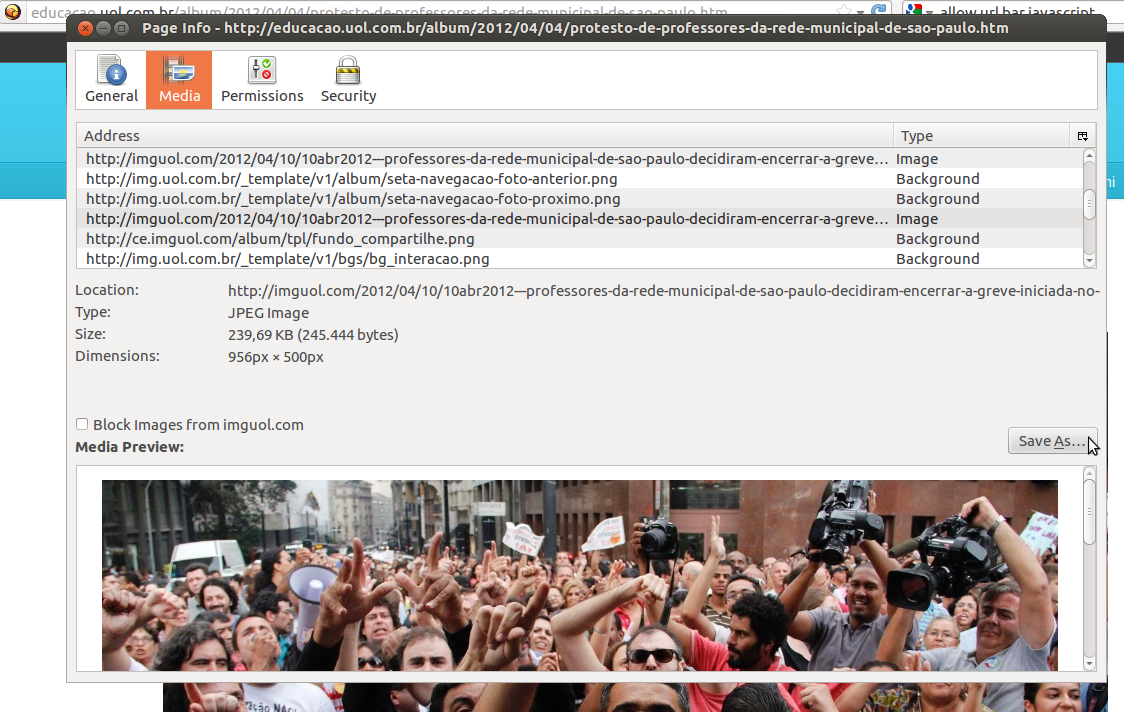
5. Se você não quiser utilizá-la e se você estiver usando Firefox, pode clicar no ícone ao lado do endereço do site na barra de endereço e aí no botão “Mais informações”. Isso vai abrir uma tela com uma seção “Mídia” onde é possível ver e salvar imagens, ícones e vídeos que seu navegador baixou para mostrar a página. Esse método funciona também para copiar vídeos HTML5, inclusive do YouTube:
Mídias da página (Firefox)
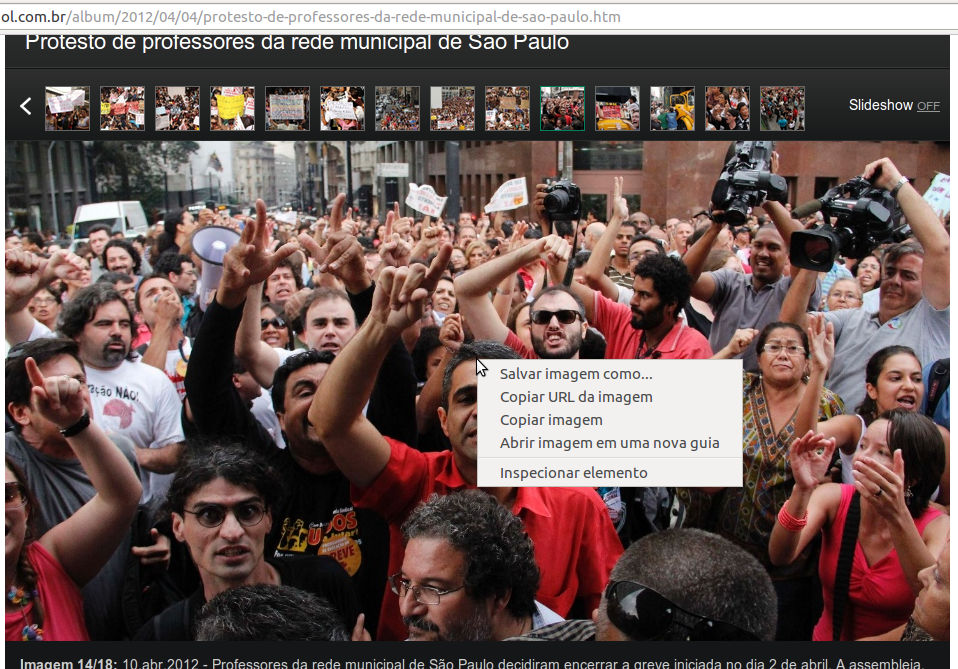
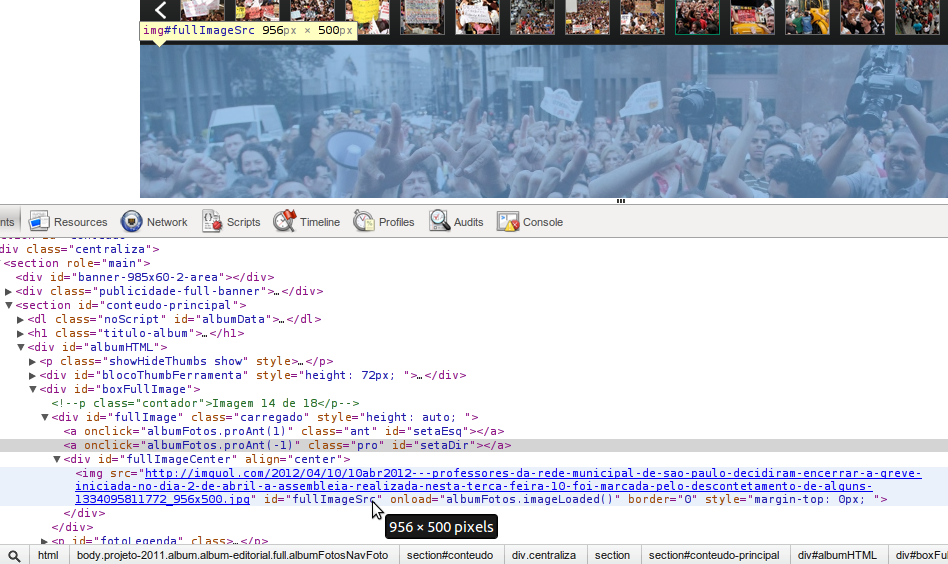
6. Se você não quiser procurar uma imagem no meio de um monte de mídias, a última versão do seu navegador deve ter um botão “Inspecionar elemento” no menu de contexto sempre que você clica com a tecla direita em qualquer lugar da página. Usando essa ferramenta é possível ver o código HTML do que você está vendo (ela é diferente e melhor do que simplesmente ver o código-fonte da página porque usando a inspeção de elementos você vê o código do momento atual, depois dos scripts mudarem as coisas). Se você pedir para inspecionar alguma coisa transparente em cima da imagem, em geral não vai ser difícil achar a própria imagem. Este screenshot é do Chrome:
Copiando URL da imagem da inspeção de elementos
Há inúmeras soluções mais nerds, mas quis manter a lista com sugestões fáceis e que não precisam de nada além do seu navegador. Alguma outra ideia simples, criativa e divertida? Blogue por aí ou me conte pra eu aumentar a lista!
{kind=link}